Web Scraping
Web scraping เป็นกระบวนการดึงข้อมูลจากเว็บไซต์โดยอัตโนมัติโดยใช้โปรแกรมหรือสคริปต์ เพื่อที่จะเก็บข้อมูลจากหน้าเว็บไซต์หนึ่งหรือหลายหน้า เช่น ราคาสินค้า, ข่าวสาร, รีวิวสินค้า, ข้อมูลต่างๆ เพื่อนำมาวิเคราะห์หรือนำไปใช้งานต่อไปได้ เทคโนโลยีที่ใช้ในการ Web scraping มีหลายอย่างเช่น การใช้ Regular Expression, BeautifulSoup, Scrapy และ Selenium ซึ่งการทำ Web scraping นั้นต้องปฏิบัติตามกฏหมายเกี่ยวกับการใช้ข้อมูลต่างๆ ของเว็บไซต์นั้นๆ ด้วย เพราะการดึงข้อมูลที่ไม่ได้รับอนุญาตอาจกระทำผิดกฎหมายเกี่ยวกับการละเมิดลิขสิทธิ์ หรือการกระทำผิดประเภทอื่นๆ ดังนั้นต้องระมัดระวังในการทำ Web scraping ให้ถูกต้อง และไม่ละเมิดกฎหมายด้านข้อมูลส่วนบุคคล หรือลิขสิทธิ์ของเว็บไซต์นั้นๆ
การทำ Web scraping สามารถทำได้หลายวิธี โดยใช้ภาษาโปรแกรมต่างๆ เช่น Python, Ruby, PHP และอื่นๆ ในตัวอย่างนี้จะเป็นการทำ Web scraping ด้วย Python โดยใช้ BeautifulSoup library เพื่อดึงข้อมูลจากเว็บไซต์ดังภาพ:
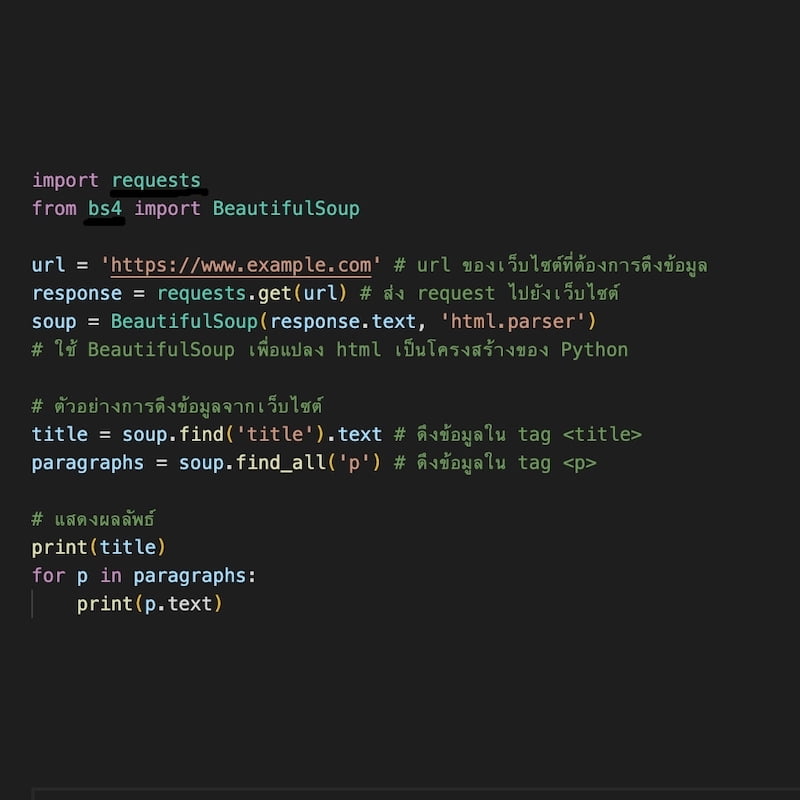
Python Scraping
โค้ดดังกล่าวจะดึงข้อมูลใน tag <title> และ <p> จากเว็บไซต์ และแสดงผลลัพธ์ออกทางหน้าจอ อย่างไรก็ตาม การดึงข้อมูลจากเว็บไซต์นั้นเป็นเรื่องที่ซับซ้อนและต้องคำนึงถึงกฏหมายด้วย ดังนั้นควรใช้วิจารณญาณในการใช้งานและปฏิบัติตามกฎหมายที่เกี่ยวข้องในแต่ละกรณี